
To consider education together with information is to question the nature of both. Can there be information without learning? Can there be education without information? Where is the distinction between education, learning and information? What do we mean by information? There are many ways of addressing these questions, and each approach opens on to new questions. My intention here is to map out the different levels of approach and their relevance to the questions of education.
Information is an important topic in contemporary education. Yet education, and particularly higher education, appears to be about much more than being 'informed' about things. Higher education is about things that matter. I chart a journey from technical the technical characterisation of information (particularly Shannon's work) through to the problem of semantic processing and sophisticated analytics of modern computer systems, through to issues of 'mattering'. I show how education effectively causes these issues to 'fold in' on each other: Shannon's distinction between medium, message and noise becomes blurred to the point where with things that matter in education, medium, message and the bio-psychosocial context of communication are inseparable. Understanding the stages by which this folding occurs provides a foundation for critique of both education and information which leads towards a politicising of technology and information.
Introduction: Does it make sense to talk about ‘information’?
If the cybernetics of Pask, Ashby, Beer and co. is now considered ‘old-fashioned’, the topic of ‘information’, with its related fields of “big data” analysis, ‘smart’ data, crowd-sourcing, social software, ubiquitous computing and so forth dominate scientific concern across disciplines. Clearly the most dramatic technological transformation has occurred in Information Technology over the last 20 years: virtually every individual in developed societies has become wired into a network dominated by global corporations, and that increasing aspects of personal life are being recorded as data which then present to those with access to the aggregated data opportunities for exploitation. The algorithms for performing this exploitation come from other data-intensive forms of research: data analysis finds itself dominating research in biology, physics, sociology, history as well as computer science. Information analysis drives the hunt for potential threats to society from terrorism to paedophilia, espionage to so-called “cyber-warfare”. In education, ‘learning analytics’ has attempted to harvest the data generated by learning systems concerning the behaviour of learners, the response to different pedagogical interventions, the effectiveness of teachers and so on. Information about students is increasingly gathered concerning the performance of institutions. The predictive successes of information-theory driven technologies like ‘Google translate’ are astonishing, reigniting the dream of a mimetic Golem-like artificial intelligence fuelled by the “crowd”. Naturally, many are worried by this. The disclosures by Edward Snowden about privacy raise the prospect of enslavement in an information society where all individuals effectively become ‘information workers’ for global corporations. At the same time, the apparent predictive success of algorithmic analysis of texts, videos, images, conversations, and so on raises deep ontological questions about the nature of the world and the possibility of analytical purchase on the most fundamental mechanisms of personal and social life. In this chapter I will argue that these ontological challenges are good questions: they challenge us to look at ourselves. At the same time, the concerns about surveillance are well-grounded. In a society which demonstrates increased inequality of wealth also demonstrates inequality in the distribution of information. But the ontological challenge is to also ask What do we mean by Information? What is the relationship between Information and Education? How does social structure relate to information?
To talk of information is to talk of something between us; in effect it is to talk of something “other”: information is a surrogate topic. So we first have to decide what ‘information’ is a surrogate for. One possibility is that information is a surrogate for theorising about agency. Deacon makes a convincing case that the challenge is to avoid homuncular thinking. It is tempting to think (in an ‘information’ age) of information as ‘stuff’ carried by the technological media which bombards agents, demanding attention, engagement and action. In effect, this is to model the causes of action. Human agents are “nodes” in a causal chain of action. In acting, humans produce more information which causes others to act. This combination of agency and information become the Worldwide Web, the TV, the press where the between-ness in the final analysis is simply signals down a wire. However, biologists use the word ‘information’ to account for codes in the genome, economists use it to characterise knowledge of the market, and physicists are increasingly talking about it role in the universe. The ambiguous surrogate world of Information becomes the stuff of screens and switches - something to be accessed, recorded, played back, absorbed and analysed.
Can there be information without learning? If information is a surrogate topic for theorising agency, then to theorise information is also to theorise learning: signals have to be interpreted, acted on, languages learnt and technologies engaged with. But then, is learning specifically human? Do cells ‘learn’ the DNA code? Does the universe understand the information contained in Hawking radiation? The questions highlight not only the poverty of our thinking about information, but also the poverty of our thinking about education. However, this has not stopped educationalists jumping on the information bandwagon as the “hand-grenade” of the internet effectively blew-up conventional centuries-old thinking about education. It is now not uncommon to find ‘access to information’ mistaken for education; “teaching” described as a kind of ‘information brokerage’; social online engagement mediated by information networks equated with classrooms; and the ‘functional equivalences’ of online learning paraded as a cheap alternative to expensive libraries and academic apprenticeship. The perpetrators more-often-than-not have been Universities themselves: ‘going online’ is seen as a way of reaching wider ‘markets’ for students. Going online becomes an engine for feeding further information about new marketing opportunities for Universities, extracting information about learner and teacher practices, informing managerial decisions for regulating professional behaviour and learner/customer management.
Despite the paucity of its theorising, educational managers and information technologists behave as if they have cracked not only ‘information’, but education too. This must in part be because information appears to be analytical and empirical in nature. Information entails measurement, and the measurement of human action provides at least some context for critiquing it. However, in disposing ourselves towards information and measurement, we immediately risk stepping into a functionalist world is as effective at blinding us to what escapes measurement as it has become in persuading us of the truth of what can be measured. A disposition towards measurement already carries us away from the critical and the existential towards functionalism.
To critique information is to challenge functionalism. Homer describes the plight of Aegeus who threw himself into the sea at the sight of black sails on Theseus’s boat. To critique information is to ask, Was it the blackness of the sails, Theseus’s thoughtlessness or Aegeus’s hastiness which caused the tragedy? Functionalism attributes rather too much to the sails! This is not to say that the sails ‘do’ nothing. To conceive that there must be something in the sails is useful – the way they are displayed, their visibility, their interpretation.
Connection and Process
At the heart of information theory is the concept of surprise. When messages are exchanged between machines, different symbols are expected to different extents. In the English language, for example, the letter E has a higher probability of appearance than the letter X. In Shannon’s information theory, the amount of information exchanged between a sender and a receiver can be calculated as the amount of information required such that the receiver could anticipate the message. Whether in speech, or the sending of electronic communications on platforms like Twitter, there is a quantifiable content of information which is an index of the surprisingness of the message. Highly surprising messages contain more information than messages that are not surprising (and so, by definition, ought to be predictable). There are different levels of surprise from the surprisingness of the sequence of letters that make up words, to the surprisingness of sequences of words, to the correlation between the surprisingness of sequences of words and the other information relating to the source of the message (like the location or time).
Claude Shannon characterised surprise as something existing between a sender and a receiver. Surprise was important to Shannon because it related to a practical issue that he was concerned with at Bell Laboratories: how to understand the relationship between the capacity of an electronic channel for transmitting information, the complexity of the information to be transmitted and the noise on the medium which might interfere with communication. He produced the following diagram:
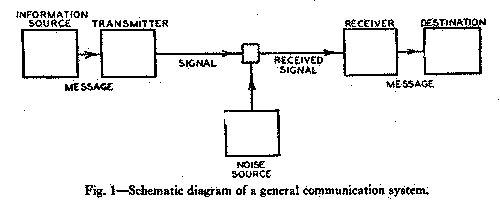
At the heart of Shannon’s theory is the idea that transmitted messages contain fluctuating levels of surprise. Messages with large amounts of surprise would require a greater channel capacity for transmission that those messages with small amounts of surprise since the receiver would be able to predict messages which were unsurprising with greater accuracy than it would messages with a lot of surprise. This focus on surprise introduced a number of mathematical properties. Firstly, the total surprise of the messages could be calculated. With this calculation of the total surprise in a message, a value could be produced for the capacity or bandwidth of the channel to successfully transmit the message.
Shannon’s calculation of information is measured as a number of ‘bits’ – individual elements (Binary dIgiTs) which can be either true or false. In any message, each letter has a probability which can be calculated as the number of occurrences of that letter divided by the total number of letters. This produces a value between 0 and 1. In order to establish the joint probability of all the letters in the message, probabilities should be multiplied together. One way of multiplying numbers together is to add the logarithms of those numbers. The base of the logarithm can be anything, but If the base is 2, then the sum of the logarithms relates to the number of individual ‘bits’ (units of true or false) which make up the information content. This logarithm number can be related to surprisingness because a letter with a high probability produces a low log value (and so low surprise) and a letter with a low probability produces high log value (and so high surprise). Shannon called this measure of ‘surprise’ Entropy, following the statistical thermodynamics of Boltzmann. This was unfortunate, but shouldn’t distract from the utility of the measure of surprise. The total entropy of a message is indicative of the bandwidth of the communication channel necessary for the message to be successfully transmitted.
An example makes this clearer: a typical Twitter message might read “I am eating breakfast”. There is surprise in the individual letters sent out in this message, which we might characterise the different letters of the possible letters as:
N
|
Pn
|
Pn * Log Pn
| |
A
|
2
|
0.1
|
0.33219
|
B
|
1
|
.05
|
0.21610
|
C
|
1
|
.05
|
0.21610
|
D
|
0
| 0 |
0.00000
|
E
|
2
|
0.1
|
0.33219
|
F
|
1
|
.05
|
0.21610
|
G
|
1
|
.05
|
0.21610
|
H
|
0
| 0 |
0.00000
|
I
|
2
|
0.1
|
0.33219
|
J
|
0
| 0 |
0.00000
|
K
|
1
|
.05
|
0.21610
|
L
|
0
| 0 |
0.00000
|
M
|
1
|
.05
|
0.21610
|
N
|
1
|
.05
|
0.21610
|
O
|
0
| 0 |
0.00000
|
P
|
0
| 0 |
0.00000
|
Q
|
0
| 0 |
0.00000
|
R
|
1
|
.05
|
0.21610
|
S
|
1
|
.05
|
0.21610
|
T
|
1
|
.05
|
0.21610
|
U
|
0
| 0 |
0.00000
|
V
|
0
| 0 |
0.00000
|
W
|
0
| 0 |
0.00000
|
X
|
0
| 0 |
0.00000
|
Y
|
0
| 0 |
0.00000
|
Z
|
0
| 0 |
0.00000
|
SPACE
|
3
|
.16
|
0.42302
|
TOTAL
|
19
|
.96
|
3.58056
|
If the message read, instead of I am eating breakfast, “I am eating #breakfast”, the # symbol is a rarer symbol in normal English, and so the amount of surprise (quantified in Shannon’s theory) is greater. However, the meaning of the message would be the same.
The information content in individual letters is but one level of surprisingness. If the receiver is a machine, and the machine is only concerned with receiving the sequencing of letter correctly, then the actual words don’t matter. However, we have become used to utilities like ‘predictive text’ such that machines have become quite good at predicting the words we type: there is also surprise in the words. If the message read “I am eating concrete”, this would be more surprising than “I am eating breakfast”, simply because “concrete” is a less common word in a corpus than “breakfast”.
In determining the surprisingness of a particular message, the context of the word in relation to other words has to be taken into consideration. One way of doing this is to pair words: some completions of the message will also increase its information content: for example, “I am eating mud”. When examining messages at a word level, there are a number of techniques for examining how surprising a particular sentence completion is. One of the most popular methods is the N-gram. In an N-gram, “I am eating mud” becomes a sequence of pairs:
[I, am]
[am, eating]
[eating, mud]
Surprisingness of a single message is not necessarily that information. However, the lower entropy messages can be established by comparing them with a much broader set of messages in a ‘corpus’ of tools like Facebook, Twitter and so on.
Given these pairings, and given a corpus with which to compare the likelihood of these pairings, the surprisingness of different messages can be compared. In a table of possible N-grams, the surprisingness of the pairing [eating, mud] will be noticeable.
Modelling the predicting brain
The ability to predict a message is dependent on a number of different factors: the nature of the message itself, the capacity of the communication channel, the amount of ‘noise’ on the channel and so on. Humans have a capacity to absorb many other kinds of contextual information in order to predict a message: this extra information is, on the one hand, ‘redundant’ because it reinforces the message that is transmitted, although extra signals like arm-waving, facial expressions, intonation, knowledge of context, information about time, and so on all contribute to the ability to predict the message being transmitted. The probability of being able to predict a message is dependent on the presence (or not) of other variables and other data. For example, the ability to predict “I am eating breakfast” concerns not only the likelihood of breakfast following eating, but also on the time of day, and the type of messages a person might have sent before.
Whilst Shannon’s formula helps to characterise the surprisingness of things, other statistical tools can help characterise the ability of a machine to predict a message. Whilst Shannon’s sender and receiver were dumb machines which didn’t ‘learn’ from the messages transmitted to them, today’s machines ‘learn’ using algorithms derived from statistics: most notably the probabilistic calculations resulting from various applications of Bayes Theorem.
Bayes theorem is a theorem of conditional probability. It concerns the probability of one variable given the presence of another variable which is in some way correlated to it. For example, used with the identification of N-grams, Bayes theorem can be used to calculate the probability of the next word given the previous word. The combination of Bayesian reasoning and Shannon entropy is effectively a combination of a technique for measuring surprise (Shannon) with a technique for 'learning' from past events such that the degree of surprise adjusts over time (Bayes). This raises many questions about the relationship between the capacity of 'learning and communicating machines' to learning and communicating human beings. Are Bayesian networks wired into evolving human communication systems analogous to brains? Might they become super-intelligent? Might the predictive capacity of computer networks begin to 'outsmart' human reasoning to the point that the machine is already ahead of the human?
These are fundamental questions which lay behind much of the early work in cybernetics. Up until quite recently, artificial intelligence had largely appeared as a curiosity rather than a significantly useful part of the technological landscape. Does this mean that teachers will eventually become redundant? Does it mean that a computer might be able to successfully predict the actions of a learner and adjust its communication with the learner such that a learning is more effective than it might with a human teacher? These are powerful questions because they challenge us to be more critical about what we mean by learning and its relationship to information. I will argue that AI can of course be useful in education (think of the power of Google Translate in the learning of foreign languages), but that higher learning is about more than being informed; it is about things that matter. However, there is a connection to be made between things that matter and information. In order to make this connection, we first have to consider the problem of meaning, and its relationship to education.
Shannon and Cybernetics
Shannon’s theory is a corollary of Ashby’s law of requisite variety. Where Ashby saw the variety of a system being the maximum number of possible states that system could be in, and that control of the system required a controlling system of equal variety, Shannon articulated that a high variety machine would transmit more surprising messages than a low-variety machine. The process of successful communication therefore becomes a homeostatic relationship between sender and receiver. Miscommunication was effectively the result of unmanaged variety. In considering noise, Shannon adds into Ashby’s mechanism an exogenous variable which unpredictably affects the variety management. The control situation becomes one where the variety of the sender and the variety of the receiver have to be increased to compensate for the effects of noise. Viewed from this perspective, redundancy is not an ‘increase in bits’, but rather an increase in functional capacity by each communicating device. In exploring this concept of redundancy, Warren McCulloch highlighted that whilst the brain is redundant by the order of about 20000:1, this redundancy is a ‘redundancy of potential command’, not a redundancy borne out by the complexity of signals produced by the brain. When considering the relationship between Shannon’s communication model and human communication, as observers we recognise the surprisingness of messages, the noise on the medium, the redundancy transmitted to compensate, and this all serves as an index of the variety of the communicating machines – which might be represented by a number of bits. However, as observers of the process, we ourselves exhibit a “redundancy of potential command” within our own brains: it is in those brains that surprisingness is registered: both the surprisingness of the messages exchanged and the surprisingness of the behaviour of the machines themselves as they exchange messages.
There are many questions about the nature of Shannon information and the role of human beings. He considered to what extent the problem off transferring information in a medium was analogous to the transfer of states of matter as it was expressed in thermodynamics. In the statistical thermodynamics of Boltzman, the measure of entropy was used to determine the certainty of matter being in a particular state in a particular place: if all matter was in one place in one state, there was low uncertainty; if it was distributed, then there was high entropy. In Shannon’s case, if a message was surprising, then it had a low probability, and therefore a high entropy; if it had a high probability, it had a low entropy. As Ulanowicz has indicated, Shannon’s meaning is precisely different from Boltzmann’s. This creates problems if we then attempt to connect issues of meaning to Shannon’s work.
Data Mining
Data Mining relates to the technologies for the storing and searching of vast quantities of data. The calculation of entropies in compression algorithms, pattern matching, machine learning and almost any sophisticated data-based operation has been fundamental to the success of Shannon’s theory. The ability to specify the ‘process’ of communicating machines in terms of selections and calculable entropy has enabled many problems of communications engineering can be broken down analytically. For example, in data compression, the principal challenge was to identify the coding with the minimal number of bits of information which could express a coding system to reproduce the entropy of an encoded message. Shannon himself puzzled over the problem of being able to determine the minimal code, but it was solved by his PhD Student, David Huffman. The Huffman code basically encodes the entropies of the symbols in a message. Compression algorithms for images, video, all use these techniques.
Data mining in images and video use different techniques to the data mining of text. The idea of a distribution translates to the ways in which waves can be transformed to encode data. For example, the use of wavelets takes a simple distribution to recursively encode data. This produces different levels of reasoning about matches. With the ability to compress data and encode entropy, come related problems of pattern-matching entropies using small samples of data. Using techniques like Discrete Wavelet Transforms the transformations of a basic wave within sections of an image can be used as a different way of encoding information, when finally the entropy encoding actually takes place.
Forecasting of both physical and social systems together with the automatic identification of surprise in electronic messages corresponds well-enough to human experiences that this process of exploration has dominated University curricula in machine learning and data mining - a move which has challenged philosophical objections with technological assertions of the efficacy of the methods. Data analysis shouts ‘science’, and in the process expectation grows that just as the natural sciences are commonly thought to have replaced philosophy’s position during the enlightenment, so now computational analysis of social data will replace metaphysics in years to come. Some of the champions of this process are philosophers: John Searle stated that consciousness research that steadily identifies the “neural correlates of thought” would eventually render metaphysics redundant. In the application of Shannon’s ideas and the relentless increase in the ability to extract useful results by aggregating apparently useless data, there is a lot at stake.
Social network ‘graphs’ display ‘nodes’ of individuals who are connected by arcs to other nodes. The arcs indicate messages exchanged between nodes. In such a graph, each node is a ‘source of declared relations’: i.e. each node exists by virtue of the messages it sends and receives. In effect, this means that a person becomes a node in a communications network. The internet affords other forms of analysis. What if a “source of declared relations” is not a person, but a document? What if the document’s declared relations can be related to the declared relations of other documents? What if documents are taken to be sources of declared relations between individuals? Different characterisations of a ‘node’ produce richer and richer analytical possibilities for what appears to be the identification of meaning. A simple example of a document making declarations is the ‘citations’ shown by one document of other documents. Seeing documents as sources of declared relations in this way means that metrics of ‘influence’ of documents, and (in particular) metrics of influence of the authors of documents (where an author is a source of these sources of relations to other sources of relations).
Various techniques used by search engines keep databases of the relations between tokens and other documents. The term-frequency, inverse document frequency measures that such tools use a way of classifying the different terms. The principal question which arises from these techniques is that given there is some correlation between the viewing of visualisations and the understanding of individuals of the phenomena represented, what does this tell about what must be going on in the heads of people whose communications, data and language is represented pictorially? The visualisations of data and our reaction to this visualisation gives us a way of being able to explore the different models of agency that are presupposed through our different theories of information.
Two Approaches to Meaning
The internet today provides us with answers to questions. Technologies for data analysis, search, compression and encryption all contribute to the efficiency of searches across data of all types. The implication of online searching is that data is ‘about’ something, and that with effective searching the relation between data and its ‘aboutness’ can be established. Search has become so ingrained in our daily technological practice that it is hard to imagine our computer technology doing anything else. The problem is that the computer-generated ‘aboutness’ of documents is an approximation, and whilst search engines continually try to optimise their performance (Bayesian reasoning again!) the need to codify large chunks of data with smaller chunks of ‘metadata’ which indicate what the larger chunk is about inevitably attenuate the true complexity of any document. In the defence of this attenuation, one might argue “how could search work if it wasn’t able to summarise what it felt documents were about?” The question invites a deeper examination of the assumed primacy of search and the provision of answers to queries.
Ashby’s homeostat was not a machine which would provide the kind of answers to questions that we are now used to, but it did provide answers of a sort to changes in input. The regulatory movements on the dials of the homeostat were indicative of a necessary process of adaptation to a particular question. This was a kind of ‘answer’. Some years after Ashby’s homeostat experiments, Stafford Beer and Gordon Pask were experimenting with biological and chemical computing devices, Beer’s system using Daphnia from a local pond which have been fed iron filings, and Pask’s solution involving a ferrous colloidal solution. In each case, the approach was to present questions as changes to input voltages, and to grasp at answers through the biological and chemical growth reactions to the change in inputs. The “information” produced as a result of this was not an attenuation of available data, but rather a new structure which had formed to make new connections in new ways. What were these structures ‘about’? What was the answer to the question? The answer lay in new suggestions as to how to develop in order to find a way of organising oneself against constraints. The curious thing about the situation with Ashby’s homeostat and Beer and Pask’s bio-chemical computers is that whilst such a system might hardly be regarded as useful, its behaviour would nevertheless be regarded as curious, even fascinating. The cause of the fascination would be the correlation between inputs and outputs. Moreover, the fascination is situated at the interface between the human system and the mechanical system. Both Beer and Pask believed that meaning lay in identifying the steady-state in a human-computer system. In such a steady state, human conduct could be guided by machine transformations in a way that avoided concepts as codified terms. However, this cybernetic approach to aboutness has been considered impractical, and given the vast power of the internet to automatically identify the aboutness of things, and to bracket-out the human side of the communication, Beer and Pask’s experiments will remain a side-show.
The contemporary problem of the ‘aboutness’ of information is related to the problem of knowledge – particularly its breaking-down into parts - the problem of reductionism. The education system has been particularly active in upholding the segmentation of knowledge and the ascription of aboutness. Through education there is the attainment of learning outcomes, the regurgitation of equations, the performance of effect skilled procedures in different disciplines: each of these are ‘semantic’ – they are about something. However, the problem (and hope) of education is that it cannot fully escape the deeper human responses to the flow of differences that shape experience. The flow of experience in education is one of conflicting and confusion differences, surprises, an ebb and flow of entropy whose meaning is far from clear and upon which the imposition of an ascribed meaning of leaves us feeling much like William Blake as he complained of “Newton, sheav’d in steel”. Whilst the aboutness of the semantic reductionism of education is easily established and upheld, the aboutness of the flow of emotional experiences in learning is hardly established.
Semantic information is right or it is wrong, and its rightness or wrongness can have important social consequences. Much social behaviour is determined by information, and indeed, economic behaviour itself has, since Hayek’s “Knowledge and Economy” been characterised as a process of information provision. There is a question as to whether false information about markets, university performance, student results, and so on actually counts as information at all. Certainly, false information creates problems for the effective operation of markets. At the same time, there is a problem in the provision of information. Hayek’s argument was that social order was related to the distribution of information in a society. Economic planning, so the argument went, was impossible because it assumed perfect information, and made assumptions about the behaviour of agents in an environment of perfect information. Such arguments have subsequently been used to justify the creation of an information market in education. Given that the meaning of information is related to social order, then in order to count as information, information has to be true. In other words, information enshrines a relationship between the data, what the data is about and its truth.
The relationship between mathematical communication theory and semantics has been enshrined in the effort to analyse “Big data” or data analytics presents the prospect of being able to determine automatically what a particular data stream is ‘about’ by analysing the differences in the data. If this is to be possible, there must be some connection between the differences made by signals and the entropy of Shannon, and the truth of data that concerns meaningfulness. Some analytical techniques appear to be quite powerful in doing this: for example, Topic Modelling is a technique for scanning a document in order to identify topics or key phrases which relate to one another across a number of different documents. The appeal of automatically identifying the ‘aboutness’ of a document is that it allows for a kind of automated ‘precis’ whereby documents can be reduced to a range of topics and categories: a kind of automatic metadata. If document analysis can identify that document x is “about terrorism”, or “about cybernetics” then semantic reduction also becomes possible.
Automated systems for document analysis can be used with other techniques for describing the aboutness of information. The “semantic web” (now called “linked data”) is an attempt to connect messages with reference. Documents could be tagged for references, and so on. However, the problem with such approaches is that interpretation of the reference term remains a topic of some dispute. One of the key features of any semantic web application is the creation of an ‘ontology’. Ontologies are basic taxonomies which classify all the different kinds of things that are possible. Yet, if we took a bunch of people to decide these things, the likelihood of them actually agreeing a list is slim. In education, taxonomies
The semantic web technologies highlight the essential difficulty with semantic information. The problem of getting people to agree suggests that there is a deficiency in the ability to describe the phenomena properly: surely, with the correct classificatory system, the ambiguity of individual interpretation can be overcome? But such a system would require it to be possible to identify from first principles the emergence of information in the minds of people. So how, from first principals, do we arise at the various symbols and systems that then cause us to argue endlessly about different interpretations? Are the laws by which those symbols come to exist discoverable? If this can be the case, there is also the problem of being able to ascertain the truth of information statements that are made. This brings us back to the problem of truth and its relation to meaning. The essential difficulty with the semantic web is getting people to agree ontologies. To say that different data mean different things to different people is to say that the truth of the aboutness of information is relative. On the one hand, there is a mapping between questions and answers, where the meaningfulness of the information is related to the truth of the answers provided.
The problem of truth of data is related to the problem of reference. However, we encounter two forms of reference: the semantic reference of metadata, topic modelling and so on, and the concept of reference as a steady-state existing between a human perception and environmental stimuli. It is in this conflict of reference that education is most exposed. Education is clearly about things: it articulates subjects for study, and publishes textbooks which are ‘about’ the subject. Yet at the same time, the process of education – the processes of teaching and learning – provoke stimuli which contribute to a ‘field’ of differences to which each individual has to react. Each person will find their own ‘steady state’ within this field. The semantic reference and the ‘steady state’ reference are co-present. Here the arguments about true and false information become very complicated, because if semantic information is inseparable from ‘steady state’ information, then a logical view as to the truth of data is impossible. The information portrayed by the media, propaganda and so forth are each constituted by a combination of semantic information and ‘steady-state’ information. However, both forms of ‘aboutness’ do not explain how it is that anything new happens: they don’t explain the ‘drive’ for knowledge – beyond a continual processes of adaptation. It doesn’t explain what matters.
The “Forming Model” and the Ontogeny of Information
Susan Oyama argues: “When something marvellous happens, whether it be the precise choreography of an instinctive behaviour or the formation of an embryonic structure, the question is always where did the information come from?’” Oyama’s focus is on the relationship between information and development. Processes of learning are processes of development, where – in response to Oyama’s question it is easy (in the first instance) to point to course notes, web pages, text books, and so on. Yet this is clearly not the whole story: there is work that goes on in learning – work of learners, work of teachers, of institutional managers, of parents and so on. Whilst it might appear that course notes, web pages and text books are each ‘about’ something, and the learner’s account of their knowledge will eventually conform to the same points of reference, the interpretation of the aboutness of a thing is itself the product of work – not just the work of perception, but the prior work of personal knowledge and growth. The work of teaching and learning operates as the efficient cause for the production of those accounts of knowledge but more importantly the relationship between this work and the information it acts on lies at the heart of what it's all about: Deacon argues that “the capacity to reflect the effect of work is the basis of reference.”
What is the work that teachers do? Teaching involves balancing interventions which at one moment concentrate a learner on an object or artefact, a task or a concept, and at another moment working to disrupt a learner from misconceptions or encouraging them to ask more questions: one aspect of education work involves creating order, the other in creating disorder. In dynamic systems more generally, Deacon identifies these two opposing forces as ‘orthograde’, where disorder arises (and entropy increases), and ‘contragrade’ where order increases and entropy decreases. Using the example of the sun’s energy which continuously bombards the planet as an orthograde force, the contragrade processes of life oppose the continual tendency for things to fall apart: physical processes lead to both to an increase in entropy – Deacon calls these “homeodynamic processes”, whilst dissipative processes also contribute to the production of order where entropy is reduced, and where constraints are amplified and ultrastable situations arise (he calls this a “morphodynamic process”). In living things entropy is reduced, and self-organised constraint production ensues through growth and development (he calls these “teleodynamic processes”). The business of making sense out of something is characterised by Deacon as a teleodynamic process, coordinated around a fixed constraint (say, a book). But this teleodynamic process sits upon morphodynamic and homeodynamic foundations. This is because a medium is a physical system, and as such is characterised by the homeodynamics of the laws of thermodynamics. Information entails work on a physical medium: the medium's consequent change in entropy tells us something. However, the work of interpretation means that even the lack of work on the medium will also convey information. It might the cause of fascination or curiosity. Deacon states:
“Despite their abstract character, information transmission and interpretation are physical processes involving material or energetic substrates that constitute the transmission channel, storage medium, sign vehicles, and so on. But physical processes are subject to the laws of thermodynamics. So, in the case of Shannon entropy, no information is provided if there is no reduction in the uncertainty of a signal. But reduction of the Shannon entropy of a given physical medium is necessarily also a reduction of its Boltzmann entropy. This can only occur due to the imposition of outside constraints on the sign/signal medium because a reduction of Boltzmann entropy does not tend to occur spontaneously. When it does occur, it is evidence of an external influence.”
The physical processes of the medium are subject to the laws of thermodynamics. The biological processes are subject to what Deacon terms "autogenesis". There remain problems of characterising the knowledge and understanding involved in communication, which is not only the work of selecting and interpreting messages, but also the work of coming to knowledge of the "medium" - the substrate of communication which is physical, biological and social. Whilst even this complexity does poor justice to the nature of communication, it is enough to note how Shannon's mathematical information based around 'surprise' cannot account for this richness of information; it is a mathematical abstraction of embodied processes whose success is attributable to its mathematical character and the fiduciary qualities ascribed by other scientists to it. Surprises arise in bodies, and whilst those bodies exhibit the thermodynamic properties of physical systems, these appear to be inseparable from those bio-psychosocial responses which transcend even the processes of Deacon's 'teleodynamics'. What then can we say of information except to say that its fundamental property is one of environmental constraint? Information is the background to being: it is an absence which is nevertheless causal on the forming of communications.
The way that the biological usage of the term ‘information’ refers to the role of DNA in processes of epigenesis provides a useful example of this. Whilst conventionally people talk as if there is information in DNA, there is little to explain the causal efficacy of this information in the interplay between DNA, RNA, proteins and enzymes in the processes of biological growth. Whilst there might be information in DNA, biological growth is characterised as an interaction with proteins and enzymes with processes being turned on and off according to a kind of computer program. We might ask, does the protein or the enzyme have information too? Do they not make a "difference that makes a difference" to the DNA? Information, wherever it resides, somehow sits in the background to the emerging form. Bateson argued that it wasn't so much the provision of information which caused growth, but rather its absence. The absence of information is instrumental in forming. Not just in biology is this situation seen: in artistic creations - particularly works of music - information might be said to exist which shapes behaviour, just as the art of rhetoric - that practice of swaying opinion and emotion - also entails a forming function.
Forming has a relation to information's 'aboutness': clever rhetoric achieves its goal when the audience understands that the underlying key message as being "about" the central point that the speaker is trying to convey. From a cybernetic perspective, a system in a stable homeostatic state, negative feedback (or negentropy, or information) is the forming agent. Such a state of forming may however have some very complex dynamics. The art of rhetoric, for example, has many cases where crowds have been convinced of the "aboutness" of the speaker's message when deeper reflection of their words and intentions would lead to critical challenge which is somehow avoided. Whilst homeostasis contributes to the aboutness of information, it is clear that there is something more that transcends it, and which some forms of rhetoric attempt to prevent. The classic case of stable complex feedback is contained in Bateson's idea of the 'double-bind': the interplay of contradictory messages at different levels where the capacity to transcend the complexity of the contradiction is prohibited, thus trapping individuals in a confusing state that renders them easily manipulated. Double binds are both homeostatic and pathological. They underline the problem that homeostasis alone cannot nurture growth, an may suppress it.
Bateson's double bind is a cybernetic mechanism which highlights a deeper problem in the functionalism of cybernetics. Even in Piaget's cybernetically-oriented learning theory, the emphasis is on emergent co-evolution with the continual seeking of homeostasis between different developing organisms. A similar epistemology is contained in Maturana and Varela's idea of 'autopoiesis', which characterises the processes whereby organisms adapt to a changing environment, coordinating their own self-maintenance and reproducing their components as organisationally-closed systems. However, to return to Oyama's concern for the 'marvellous', or indeed the surprising, both Maturana and Varela's model and Piaget's learning theory account poorly for the unpredictable and surprising twists and turns that are experienced in learning as much as they are in biology. The adaptation processes that leads to the humming bird having a sticky beak (facilitating pollination), or the extraordinary life-cycle of the toxoplasma cannot simply be down to a homeostatic mechanism: the model can only address those aspects of adaptation which are reactive.
This suggests that living things do more than simply maintain their stability. The suggestion by Deacon, Kauffman, Ulanowicz and others is that organisms in the process of maintaining stability also catalyse not only their own developmental processes, but also the development processes of other organisms in the environment. Behind Deacon's idea of autogenesis (which he contrasts with autopoiesis), there is both adaptation as well as autocatalysis. Ulanowicz characterises these processes as 'redundancies' whose interaction contributes to a top-down causal mechanism running alongside the bottom-up causal mechanism of co-evolution. In this way, the hummingbird gets its beak as a result of the interaction between the autocatalytic aspects of both the hummingbird and the flower.
Where do we locate information in this dual mechanism of homeostasis and autocatalysis? Whilst we might locate the aboutness of a homeostatic process, the form and flow of events and sense-making is driven by the interaction between this and the dissipative dynamics of redundancy and autocatalysis. The absence of any signals which might be said to be about something (for example, the absence of a student's homework) is at the same time the production of redundancies which can catalyse new processes of interpretation and stimulate new action. In this way, the homework that isn’t submitted, the student who is absent, the email that is unanswered are each informative and powerfully causal.
Deacon's approach to this situation is to consider the different levels of interaction in turn. First, the physical energy of information is something that can be articulated through Boltzmann’s statistical thermodynamics. If some physical work has been done to the medium to create some kind of change of state in it, then it means that some agent must have acted upon it, and the news of the agent’s acting is informative (although this is dependent on the capability of the individual to determine that something has changed in the medium). Secondly, Shannon’s information takes the physical differences of the medium and translate them to messages which produces patterns of surprises. Thirdly, the selections of messages sent and transmitted transform themselves over time through a process that is essentially evolutionary. Deacon articulates that information may have entropies and structures, but it also has a continuous form which emerges over time. The agents for the transmission of that form are not simply the information connections between the individuals concerned, but also the things which are absent: the context for the selections that go to making up the message.
The different levels of structure are deeply connected. For example, Shannon's information theory, in being closely related to Ashby's concept of homestatasis is little more than the coordination of senders and receivers. In Ashby's terms, it makes little sense to talk about the thing that happens between the different elements in the homeostat as 'information' except to say that each element adjusts its operations to absorb the variety produced by its neighbours, whilst at the same time producing variety for those neighbours in turn to absorb. In other words, Shannon communication is co-evolving coordination of operationally-closed systems. Indeed, the very topic of 'information' refers to the particular state of homeostasis that exists in the ongoing discourse about the ways in which organisms (human) coordinate their affairs with one another: "information" is the aboutness of human coordination.
This, however, raises a more fundamental concern about human affairs and the relation of information to them. Information might be the "aboutness of human coordination", but not all processes of human coordination are considered to be related to information, and fewer still are considered to carry the kind of semantic information that might be considered to be useful. The different perspectives on information are effectively different ways of framing agency. Both the approaches of Deacon and Floridi raise awareness to the fact that the discourse about information is of many types (Shannon, semantics, biological, etc) but each of these in turn present different aspects on agency. However, if we are to talk about being human, being a concrete person and not an agent for the promulgation of information (of whatever type), then it is not the aboutness of things which appears to be operative, but rather the fact that some things really matter. There is a relationship between information, events, social order and agency where people act in the clear knowledge of what they must or must not do: some things really matter.
Information and Concern
Some things matter to people. We may be able to determine the meaning of things and the meaning of information, but information like “your visa has expired”, or “your academic department has been closed” or “your daughter has been seriously burnt in an accident” is information which really matters. The question is, how is this information more significant than information like “Barack Obama is the president of the United States” or “it is 12 o’clock”? What is it about our apprehension of information which means that some things we discover make us panic, feel sick, bring relief, or make us excited? Even information about the time might do this if (say) we have a deadline to meet. Is it a property of information that it can have this effect? Can the informing properties be separated from the context of the individual interpreting it?
How is mattering different from reference? The problem settles on the extent to which the determining of aboutness is embodied. Mattering involves the churning of stomach muscles, cramps and other physical agonies. It causes violence, passion, exuberance. It’s in the guts – the matter of the body. Meaning, by contrast is largely in the head. The aboutness of information is selected in brains and stated in conversation. However, meaning and mattering are related. It is sometimes a surprise to discover that something really matters to somebody. Their emotional responses will reveal it. In doing so, they reveal information about the constraints operating on a person: constraints which are understood because other people have bodies too and ‘know how it feels’. Mattering is shared – it is the cognition of mutual constraints.
Meaning creates a dichotomy: what means x also means that there are things that don’t mean x. Feelings, on the other hand, are not scarce but abundant: everybody experiences grief, heartbreak, anxiety, fear. The scarcity that informing creates can result in the emotional response of things that matter. Daughters, visas, jobs and deadlines are scarce and so informing of a terrible threat to them is devastating. More broadly, what Marx describes as ‘alienation’ is precisely the interface between information and mattering. The rationalisation of capitalist economy creates scarcity which matters to people: implicit threats to safety, well-being, housing, security, as well as the creation of new scarce things which people might covet, are all conveyed by the information of capitalism. The expression of what matters is suppressed, with a rational alternative offered whereby mattering is short-circuited by the rationalistic meaning of financial calculation.
This process of short-circuiting mattering with rationalistic meaning is also a feature of modern education. The rationalisation of education has increasingly led to technocracy, where as Horkheimer argues:
“the individual's self-preservation presupposes his adjustment to the requirements for the preservation of the system. He no longer has room to evade the system. And just as the process of rationalization is no longer the result of the anonymous forces of the market, but is decided in the consciousness of a planning minority, so the mass of subjects must deliberately adjust themselves: the subject must, so to speak, devote all his energies to being 'in and of the movement of things' in the terms of the pragmatistic definition.”
The process in education is well-described by Andrew Sayer:
“In universities, research and teaching, as well as a host of other activities, are increasingly audited, rated and ranked. Teaching comes to be modelled as a rational process of setting 'learning objectives', deciding how these are to be 'delivered', designing assessment procedures that test how far students have achieved the specified 'learning outcomes', as if courses consisted of separable bits of knowledge or skill that could simply be 'uploaded' by students. The whole technology is intended to allow the process to be analysed and evaluated. Teaching is therefore treated much as a production engineer might treat an industrial process - as capable of being broken down into rationally ordered, standardized, measurable units, so that wastage and inefficiency can be identified and eliminated, and quality improved. A general, abstract technology is thus applied to every course, from aesthetics to zoology. Just what the learning objectives are apparently does not matter, as long as a rational, means-ends analysis is used to make sure that they are met. Instead of seemingly inscrutable processes controlled by unaccountable producers, we have supposedly rigorous methods for opening the business of education to public view and comparison.”
The mechanism whereby rationalism supplants authentic human response towards what matters are poorly understood. Deacon complains that
“Perhaps the most tragic feature of our age is that just when we have developed a truly universal perspective from which to appreciate the vastness of the cosmos, the causal complexity of material process, and the chemical machinery of life, we hjave at the same time conceived the realm of value as radically alientated from this seemingly complete understanding of the fabric of existence. In the natural sciences there appears to be no place for right/wrong, meaningful/meaningless, beauty/ugliness, good/evil, love/hate, and so forth. The success of contemporary science seems to have dethroned the gods and left no foundation upon which unimpeachable values can rest.”
Deacon’s quest has been to situate value and concern within more fundamental mechanisms of information. In his philosophy, it sits as the most evolved aspect of sentience, sitting upon more basic thermodynamic mechanisms. However, it might be that this hierarchical model of information is upside-down: that the embodied processes of mattering are where things start, and that rationalistic information grows from this. For most teachers, who walk into a classroom and look into the eyes of their students and read their body language before embarking on quadratic equations, this order of things may make more sense.
Inverting Deacon’s information means getting to grips with mattering before getting to grips with reference. Understanding communications which are effectively without reference is a good starting point. This is why Alfred Schutz was particularly interested in the way that music communicates, since, music expresses things which don’t appear to be about anything (Steven Pinker calls music “cheesecake for the mind” for the reason), and yet it communicates something which is felt in bodies. Schutz argues that the musical communication process, whether between composer and performer, between performers or between audience and performers is one of mutual appreciation of the flow of inner time and inner life:
“We have therefore the following situation: two series of events in inner time, one belonging to the stream of consciousness of the composer, the other to the stream of consciousness of the beholder, are lived through in simultaneity, which simultaneity is created by the ongoing flux of the musical process. […] this sharing of the other's flux of experiences in inner time, this living through a vivid present in common, constitutes […] the mutual tuning-in relationship, the experience of the "We," which is at the foundation of all possible communication. The peculiarity of the musical process of communication consists in the essentially polythetic character of the communicated content, that is to say, in the fact that both the flux of the musical events and the activities by which they are communicated, belong to the dimension of inner time.”
Teaching and learning involves a similar ‘polythetic’ process. Schutz’s description of making music together could equally apply to the face-to-face environment of the classroom:
“making music together occurs in a true face-to-face relationship - inasmuch as the participants are sharing not only a section of time but also a sector of space. The other's facial expressions, his gestures in handling his instrument, in short all the activities of performing, gear into the outer world and can be grasped by the partner in immediacy. Even if performed without communicative intent, these activities are interpreted by him as indications of what the other is going to do and therefore as suggestions or even commands for his own behaviour.”
Musicians (classical at least) must be coordinated by the codification of the score and rational agreement as to what is to be done at particular moments. In education, the rational meaning of the curriculum serves as the framework for the polythetic experiences of the classroom. Effectively, rational information articulates scarcity: the scarcity of ‘getting it right’, or being accepted by peers and teachers and so on. The scarcity matters: it is felt in the body – either through the excitement or elation of being able to perform the requisite skills or knowledge, or in becoming despondent at the inability to perform. Teachers notice the body signs. Building the confidence of a student usually involves using information to declare scarcity which is “less scarce”. Indeed, it may invoke some kind of shared constraint – something which binds learners and teachers together; something which is universal or abundant. Conviviality is a special case of the relationship between meaning and mattering where the meaning of things is deeply embedded in the shared understanding of the constraints that bear upon all.
Information and Education: Some conclusions
The challenge for a theory of information lies in the fact that idealistic thinking about information, believing it to be quantifiable, to identify and codify referents, to define targets, to abstract meaning from data, and so on, all lead to a fundamental top-down-ness of decision-making which overrides the body, and individual identity. In doing so, it can establish the conditions for the continual reproduction of mechanisms that lead to greater division in society. The powerful technologies of Bayesian reasoning, and entropy calculation can play an important role in this process, and if we are not alert to how they manipulate our daily communication situation, then we face serious consequences with regard to the ways in which we live. Whatever the technologies we have, ultimately powerful human beings make decisions. However, such decisions are taken in a context of constraint, and the major constraint is the information environment which is constituted increasingly by powerful semantic and analytical technologies. If we are not alert, these technologies can shape the political ecologies within which decisions are taken. On the other hand, it is equally possible that powerful analytical technologies help to establish new forms of governance which are more socially equitable.
A deeper question concerns the empirical basis for the identification of meaning, mattering and the connection between empiricism and the practical reality that is being revealed by current trends in data analysis. Experiment and science is the means by which information is revealed by events and realisations are shared between observers. The shared eureka moment is the moment when physical constraints shift producing a change in the explanatory narrative which in turn produces a realisation of shared transformation of inner worlds. This is the level of mattering. At this level education becomes capable of situating information and technology and turning it into an object for political debate.
No comments:
Post a Comment